

0. 들어가기 전에
이번 주부터 백엔드 프로그래밍을 한다. 백엔드 프로그래밍에 앞서 했던 java 및 SQL에 대한 이론은 아래를 참고해주기 바란다.
[Java 풀스택 개발자] Java의 용어와 개념: 낯선 Java를 친숙하게 만들어보자!
[Java 풀스택 개발자] Java의 용어와 개념: 낯선 Java를 친숙하게 만들어보자!
0. 들어가기에 앞서본래는 특별편인 React 실전으로 먼저 만나려고 했다. 그러나 생각보다 만들려던 것의 규모가 커지면서 다음 기회에 포스팅하게 되었다. 따라서 이번 주는 한국의 백엔드 중심
bbbbabbbababababa.tistory.com
[Java 풀스택 개발자] SQL편: SQL의 작동원리와 기본 문법
[Java 풀스택 개발자] SQL편: SQL의 작동원리와 기본 문법
0. 들어가기에 앞서React 실전에 대한 글을 쓰려고 했지만 기간이 많이 지나기도 했고 여러 모로 고민되어 이것은 작업일지가 될듯 하다. 그러하여 오늘은 SQL에 대해서 살펴볼 예정이다. 먼저 SQL
bbbbabbbababababa.tistory.com
그러면 이번 시간에는 무엇을 할까? 바로 본격적으로 백엔드 프로그래밍, 동접 웹 프로그래밍을 통한 웹 애플리케이션 작성을 시작하는 것이다. 따라서 이번 시간에는 백엔드 프로그래밍에 대한 기초 이론을 다시 다지고, 그와 함께 실무에서는 무엇을 주의하면 좋을지에 대해서 적어보고자 한다.
이번 시간에는 실무 중요 포인트만 적을 예정이지만, 앞으로는 각 항목마다 실무 노트 부분, TIP 부분을 조금씩 적어서 채워나갈 예정이다.
1. 웹 애플리케이션이란 무엇인가?
웹 애플리케이션이란? 사용자의 웹 브라우저에서 실행되는 소프트웨어를 의미한다. 한 마디로 우리가 사용하던 프로그램이 웹이라는 것으로 작동하는 것이다. 이 말을 들으면 바로 이런 생각을 하게 될 것이다.
어? 웹 사이트랑 뭐가 다르지?
웹 사이트는 정적 웹 프로그래밍을 이용한 것을 의미하며, 웹 애플리케이션은 동적 웹 프로그래밍을 이용한 것을 의미한다. 이 정적과 동적에 대해서는 조금 나중에 설명하기로 한다. 이 동적과 정적을 떠나서 그것의 결정적인 차이는 바로, 상호작용성에 있다. 바로 웹 사이트는 유저가 일방적으로 사이트에 '게시'된 정보를 읽어 정보를 취득하지만, 웹 애플리케이션은 이용자가 특정 작업을 하면 그것을 바로 '수행'하여 결과를 보여주는 것이다. 전자로는 위키, 뉴스 페이지, 블로그 등이 있고, 후자로는 이메일, 지도, 검색엔진 등이 있다.

그러나 이런 구분은 점점 사라지는 추세이다. 많은 웹 서비스들이 두 가지를 모두 겸하는 경우가 많기 때문이다. 따라서 우리가 지금 쓰고 있는 대부분의 사이트들은 웹 사이트이자 웹 애플리케이션이라고 해도 좋다. 그럼에도 동적 웹 프로그래밍이라는 개념은 중요하게 작용하는데, 이에 대해서 말해본다.
2. 동적 웹 프로그래밍이란?
동적 웹 프로그래밍Dynamic Web Programming을 말하기 전에 일단 정적 웹 프로그래밍Static Web Programming을 다룰 필요가 있다. 정적 웹 프로그래밍이란, HTML과 JS, CSS를 저장하고 브라우저에서 요청한다면 이를 전달하는 방식을 의미한다. 익숙한 것들이라 생각하면 맞다, 바로 프런트엔드에서 사용하는 것이다. 이러한 정적 웹 프로그래밍은 서버에서 내용을 매번 만들어 내지 않고, 미리 만든 파일을 그대로 전달하기 때문에 구조가 단순하고 속도·안정성 면에서 유리한 면이 있지만, 한계점도 명확하다.
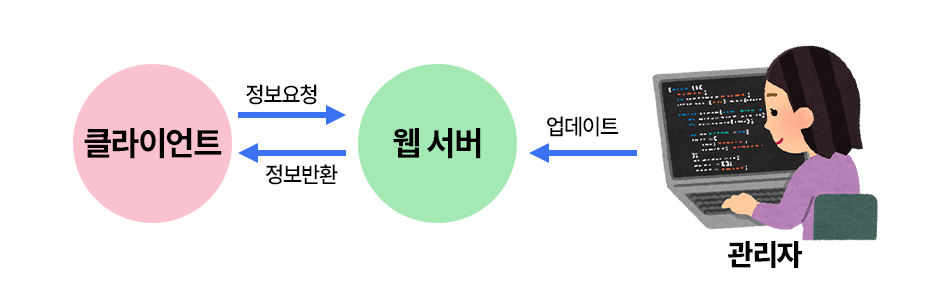
바로 그 한계점은 '파일을 그대로 전달한다는 지점'이다. 관리자 입장에서 추가, 삭제, 수정을 하기 위해서는 소스를 직접 수정해야만 하고, 이 때문에 정보를 전달하는 속도(업데이트 속도)가 늦어진다. 그리고 사용자 또한 일방적으로 정보를 받을 수밖에 없기 때문에 불편하게 된다.
동적 웹 프로그래밍은 이걸 보완한다. 클라이언트의 요청이 있을 때, 데이터베이스로부터 실시간 정보를 얻어 클라이언트에게 전송한다. 처음에 이 동적 웹 프로그래밍 방식은 바로 CGI(Common Gateway Interface)를 사용하였다. CGI는 서버와 외부 프로그램 사이의 통신 규칙이다. 사용자가 웹 브라우저에서 요청을 보내면, 웹 서버가 요청을 받고 자신이 처리하기 어렵다 판단하여 CGI 프로그램을 실행, CGI 프로그램이 처리한 것을 받아 서버가 사용자에게 보여주는 것이다.

다만 외부 프로그램이다보니 프로세스 생성 오버헤드가 존재해, 접속자가 많아지면 서버가 과부하로 뻗어버리는 단점이 있게 된다. 따라서 현재는 CGI를 사용하고 있지 않고, WAS 즉, 웹 애플리케이션 서버를 사용하고 있다.
3. 웹 서버와 WAS의 차이
그러면 웹 서버와 WAS의 구체적인 차이가 궁금해질 것이다. WAS는 CGI의 한계 때문에 탄생했다고 하지만, 왜 웹 서버와는 분리되어 보이는 걸까?
먼저, 우리 수업에서는 현재 WAS로서 톰캣(TOMCAT)을 사용하고 있다. 이 톰캣을 이용하지 않고 동적 프로그래밍으로 된(.jsp와 같은) 파일을 실행하면 내용이 보이지 않게 된다. 하얀 화면만이 보이게 되는데, 이걸 보이게 하는 것이 바로 WAS의 역할이라고 할 수 있다. WAS는 동적 콘텐츠를 생성한다. 요청에 따라 데이터를 가공하여 HTML을 만들어주는 것. 그게 WAS와 웹 서버의 차이라고 할 수 있다.
그러면 이런 의문이 들 수도 있다.
WAS가 동적 처리를 잘하면 웹 서버는 필요 없는 것 아닌가?
그러나 웹 서버 또한 필요한 이유는, 다음 세 가지 관점에서다.
(1) 부하를 분산해준다.
정적인 파일(이미지 등)은 웹 서버가 빠르게 처리하고, 복잡한 계산이나 DB 작업만 WAS가 전담하게 해 전체적인 속도를 높인다.
(2) 보안을 강화할 수 있다.
외부 사용자가 DB가 연결된 WAS에 직접 접근하지 못하도록 웹 서버가 방패 역할을 할 수 있다.
(3) 오류 대책이 쉬워진다.
WAS가 오류로 멈추더라도 웹 서버 자체에서 오류 페이지를 띄우거나 다른 WAS에게 넘겨 서비스 중단을 막을 수 있다.
이 때문에 웹 서버와 WAS를 동시에 사용하며, 서로 소통함으로써 공존하고 있다.
컨테이너
기술적으로 WAS와 웹 서버의 차이를 만들어내는 것은 바로 컨테이너Container라고 할 수 있다. WAS에는 '서블릿 컨테이너'가 존재하는데, 이 덕분에 WAS가 동적 프로그래밍이 가능해진다. 서블릿 컨테이너들이 하는 역할은 다음과 같다.
(1) 생명주기 관리 (Life Cycle Management)
서블릿 클래스를 로딩하고, 객체를 생성(init)하고, 요청을 처리(service)한 뒤, 쓸모없어지면 소멸(destroy)시키는 모든 과정을 알아서 관리한다.
(2) 통신 지원 (Communication Support)
원래 웹 서버와 통신하려면 소켓(Socket)을 만들고 포트를 연결하는 복잡한 과정이 필요한데, 컨테이너가 이 복잡한 네트워크 통신을 API로 제공해 준다.
(3) 멀티스레딩 지원 (Multithreading)
사용자가 동시에 100명이 접속하면 컨테이너가 알아서 100개의 스레드를 생성해 요청을 처리한다. CGI처럼 프로세스를 새로 만드는 게 아니라, 기존 자원을 나눠 쓰기 때문에 효율적이다.
(4) 보안 및 선언적 관리
보안 설정을 코드 안에 일일이 짜지 않고, 설정 파일(xml 등)을 통해 관리할 수 있게 도와준다.
4. HTTP 요청/응답
먼저 HTTP(HyperText Transfer Protocol)에 대해서 재정의할 필요가 있다. 우리의 주소창을 보자. 그러면 아래와 같은 구성으로 이루어져 있다.

HTTP는 여기서 프로토콜이다. 최근에는 http + security(인증서 보안)하여 https 연결이 기본이 되었지만 http가 기본임은 부정할 수 없다. 프로토콜이란, 웹 브라우저(클라이언트)와 서버가 서로 데이터를 주고받기 위해 사용하는 공통의 약속이라고 할 수 있다. 이 HTTP의 큰 특징은 바로 비연결성과 무상태성이다. 비연결성(Connectionless)은 클라이언트가 요청을 보내고 서버가 응답을 마치면 즉시 연결을 끊는다는 의미이며, 무상태성(Stateless)은 클라이언트의 이전 상태를 기억하지 않는다는 것이다. 따라서 각각 요청이 독립적이라고 할 수 있는데, 이러한 '무상태성'을 보완하여 사용자를 식별하고 상태를 유지하기 위해 쿠키(Cookie)와 세션(Session)이라는 기술을 사용한다.
HTTP 요청 및 응답에서 사용되는 데이터는 다음과 같이 나타낼 수 있다. 바로 헤더(Header)와 바디(Body)다. 다만 GET 방식의 경우 이 헤더와 바디를 사용하지 않고 URL 쿼리를 이용한 요청 및 응답을 하게 되는데, 이 부분은 아래 메서드 부분에서 설명하겠다.
헤더Header는 데이터를 보내는 사람, 받는 사람, 그리고 데이터의 '성질'에 대한 메타데이터가 담긴다. 헤더는 메모리(RAM)에 일시적으로 머물다가, 서버가 요청을 받는 순간 메모리에 올라온다. 서버는 이 헤더를 읽고 누가 보냈는지, 어떤 데이터를 원하는지를 분석한다.
바디Body는 클라이언트와 서버가 실제로 주고받고자 하는 핵심 내용이 들어가는 곳으로, 요청/응답의 핵심적인 부분이라고 할 수 있다. 바디는 서버가 처리해야 할 실제 데이터이기 때문에, 바디 내용을 읽어 DB에 저장하거나 변수에 할당한다.
따라서 HTTP 요청/응답은 다음과 같다고 할 수 있다.

5. HTTP 메서드(GET/POST)와 멱등성
대표적인 HTTP 메서드는 GET과 POST가 있지만, 실제로 주요 메서드는 9가지 정도가 된다. GET과 POST 외에도 PUT, PATCH, DELETE, HEAD, OPTIONS, TRACE, CONNECT와 같은 메서드가 있다. 이렇게 많은 메서드가 있음에도 POST와 GET만이 사용되는 이유가 있을까?
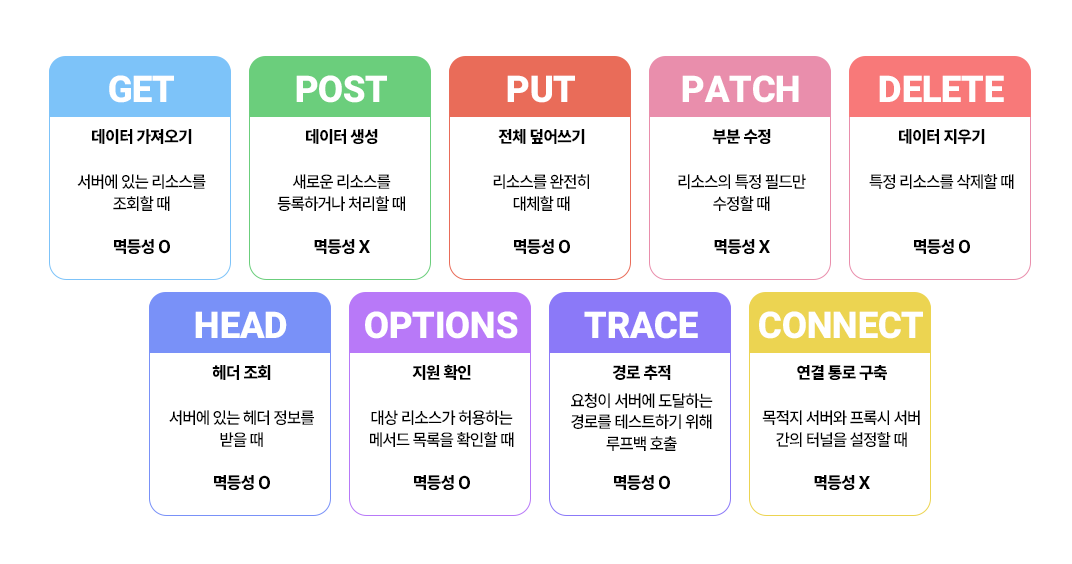
이유는 여러 가지 있는데, 결정적인 이유는 form태그의 한계 때문이다. <form> 태그는 method 속성으로 GET과 POST만 지원하고 있기 때문에, GET과 POST를 사용하게 된다. 왜 form이 method 속성으로 GET과 POST만 지원하냐면, HTML 1.0~2.0, 즉 HTML 초기에는 사용자가 할 수 있는 일이 두 가지뿐이었기 때문이다. 즉, 서버에 있는 문서를 가져와서 읽는 용도로 사용하는 GET과, 게시판에 글을 쓰거나 회원가입 양식(Form)을 채워 보내는 용도의 POST만으로도 충분했기 때문에 form은 이 둘만 지원하게 된 것이다. 그리고 사실 GET과 POST만으로도 나머지 메서드를 흉내낼 수가 있기 때문에 굳이 다른 메서드를 사용할 이유가 크게 없다.
그렇다면 GET과 POST는 무슨 차이가 있을까? 그 전에 이 차이의 중점인 멱등성(Idempotency)에 대해서 짚고 넘어가야 한다. 멱등성은 연산(요청)을 여러 번 수행해도 결과가 처음과 똑같은 성질을 의미한다. GET의 경우는 멱등성이 존재하지만, POST는 존재하지 않다. 즉, GET은 10번이든 100번이든 한 차례를 한다고 하여 상태가 변화하는 일은 거의 없다. 반면 POST는, 10번, 100번하면 모두 다 적용이 된다. 우리가 등록 버튼을 여러번 연속으로 누르면 연속으로 같은 글이 등록되는 것과 같다.
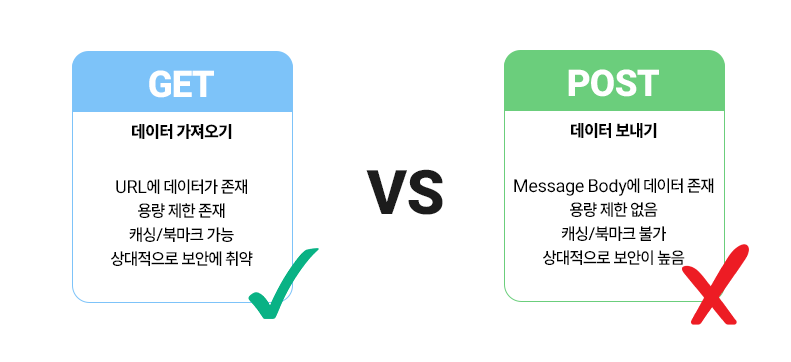
이 차이는 바로 데이터를 다루는 방식 때문이다. GET의 경우 URL의 쿼리를 읽어와 파라미터로 쪼개어 각 데이터를 받아들인다. 따라서 URL에 GET으로 보내거나 받는 데이터가 노출되어 있다. 이 덕분에 우리가 보고 있는 페이지의 URL을 그대로 복사해서 붙여넣어도 그 페이지에 그대로 갈 수 있다. URL을 수십 번 불러온다고 해서 변화가 매번 일어나지는 않을 것이다. 이 때문에 멱등성이 존재한다고 할 수 있다.
하지만 URL에 데이터가 노출된다는 건 쉬이 URL을 통해 데이터를 읽어낼 수 있다는 뜻으로, 아이디나 패스워드처럼 민감한 정보에는 사용하기 어렵다. 반면 POST는 URL에 저장하지 않고, 이 때문에 GET의 장점인 저장 등이 불가능하며, 대신 보안은 높아져 민감한 정보에는 사용하게 된다. 양쪽 다 사용처가 다르기 때문에 둘 다 사용하게 된다고 볼 수 있다.
6. Cookie와 Session
위에서 HTTP의 무상태성을 해결하기 위해서 쿠키Cookie와 세션Session이 존재한다고 말했다. 둘은 저장한다는 지점에서 비슷해보이지만 다른데, 먼저 비슷한 지점을 이야기해보면 데이터를 보관한다는 점, 그리고 HTTP 헤더를 이용한다는 것이 있다. 이 둘은 데이터를 보관할 때 key와 value를 사용하여 저장한다.
그러면 이 둘이 어느게 다르냐면, 바로 저장하는 곳이다. 쿠키는 브라우저에 저장된다. 반면 세션은 서버(WAS)에 저장된다. 이에 따라 쿠키는 데이터 자체가 브라우저에 저장되게 되며, 세션은 데이터의 열쇠가 되는 세션 ID가 브라우저에 저장되어, 이후 서버에게 요청하여 데이터를 불러오는 형태가 된다. 이렇게 들으면 쿠키쪽이 덜 번거롭고 빠를 테니 좋아보이지만, 이런식으로 브라우저에 쿠키를 저장하게 되면 CSRF 문제가 생김을 바로 지난 TIL인 시큐어 코딩에서 다룬 적이 있다.
[Java 풀스택 개발자] 시큐어 코딩편: 개발자가 알아야 할 웹 보안#4.CSRF (Cross-Site Request Forgery)
[Java 풀스택 개발자] 시큐어 코딩편: 개발자가 알아야 할 웹 보안
0. 들어가기 전에최근 몸이 안 좋았다. 공부를 게을리하지는 않았지만 수업 진도를 따라가는 것만으로도 버거워서 따로 강의 일지를 적는 것도 부담이 되어 좀 쉬었다. 하지만 TIL만큼은 계속 이
bbbbabbbababababa.tistory.com
따라서 중요한 정보 같은 경우는 세션으로 저장하는 것이 좋다. 그 외에도 쿠키 같은 경우는 이용자가 생명주기를 정할 수 있지만, 세션은 브라우저를 끄면, 혹은 서버에서 지정한 시간이 지나면 사라진다. 로그인 중에 30분이 지나면 로그인이 풀리게 되어 있는 사이트들이 있는데(대표적으로 정부 사이트) 이렇게 세션을 이용하는 것이다.
그러면 실제로 웹 애플리케이션에서 이 세션을 이용하여 로그인 상태를 유지하는 세션 기반 인증(Session-based Authentication)은 어떻게 되는 걸까? 첫 번째로, 세션을 생성한다. 사용자가 아이디와 비밀번호를 보내면, 서버는 이를 대조하고 해당 사용자가 맞는지 확인한다. 그 후 서버는 자신의 메모리에 해당 사용자의 로그인 정보를 넣어둔다. 그리고 이 세션 ID를 발급하여, 브라우저에 쿠키 형태로 넣는다. 마지막으로, 사용자가 새로이 요청할 때마다(페이지를 옮기는 등) 브라우저는 저장된 쿠키 형태의 세션 ID를 꺼내 요청 헤더에 보낸다. 그러면 서버가 이를 읽고 로그인 정보를 대조한 뒤 로그인을 계속 유지시켜주는 것이다.
7. Servlet
서블릿Servlet은 자바를 사용해 웹 페이지를 동적으로 생성하는 서버 측 프로그램을 말한다. 위에 있는 CGI의 대체 중 하나라고 보면 되는 데, 그 중 자바 언어를 지원하는 것이다. WAS에는 모든 서블릿 컨테이너를 가지고 있고, 이 서블릿을 통하여 로직을 실행한다. 서블릿의 코드 구조는 다음처럼 이루어진다.
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
// 1. @WebServlet: 이 서블릿을 호출할 주소(URI)를 정한다.
@WebServlet("/hello")
public class HelloServlet extends HttpServlet { // 2. 반드시 HttpServlet을 상속받아야 한다.
// 3. doGet: 브라우저가 GET 방식으로 요청을 보낼 때 실행되는 메서드.
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// 4. 응답할 데이터의 타입과 인코딩 설정
response.setContentType("text/html; charset=UTF-8");
// 5. 브라우저에 글자를 출력하기 위한 도구(출력 스트림) 꺼내기
PrintWriter out = response.getWriter();
// 6. 실제 HTML 내용을 작성해서 브라우저에 전송
out.println("<html>");
out.println("<head><title>Hello Servlet</title></head>");
out.println("<body>");
out.println("<h1>안녕하세요! 서블릿입니다.</h1>");
out.println("<p>이 화면은 자바 코드가 만든 동적 페이지입니다.</p>");
out.println("</body>");
out.println("</html>");
}
}
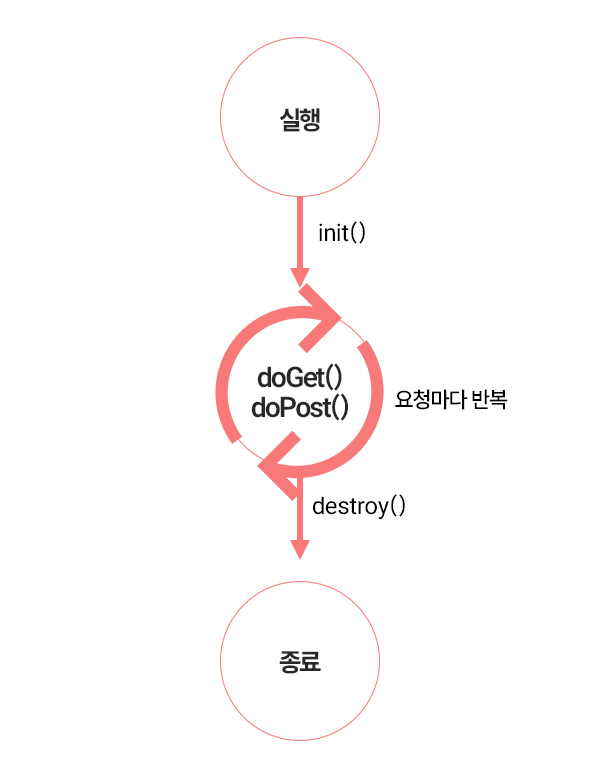
먼저 HttpServlet을 상속받아야 한다. 그리고 @WebServlet을 통해 URI를 정한다. 그리고 init, service(주로 doGet이나 doPost처럼 HTTP메서드에 따라 정해진다), destroy의 생명주기에 따른 메서드를 만든다. 주로 되는 출력은 service에 있는 것으로, out.println를 이용하여 출력하게 된다.
이 Servlet의 생명 주기는 init() → service() → destroy()로 이어진다. init은 서블릿 객체가 처음 생성될 때 딱 한 번만 실행된다. 이것은 서블릿이 일하기 전에 필요한 초기화 작업을 해준다. 전부 완료 되었다면 실제 업무를 수행하는 service()가 되는데, 말했다시피 HTTP 메서드에 따라 doGet()이나 doPost()를 호출해준다. 마지막으로 destroy()는 마지막에 서블릿이 더 이상 필요 없어져 제거되기 직전에 실행된다. 서블릿이 사용하던 자원을 안전하게 닫고 정리한다.
리다이렉트Redirect와 포워드Forward
또한 서블릿은 요청을 처리한 후 페이지를 이동시킬 수 있는데, 그 방법은 리다이렉트Redirect와 포워드Forward가 있다.
먼저 리다이렉트는, 서블릿이 브라우저에게 재접속에 대한 명령을 내리는 방식이다. 이 때문에 URL의 주소가 변경되어야 하며(브라우저가 이에 따라 이동해야 하므로), 요청 데이터(Request)는 사라진다. 속도는 이러한 재접속 때문에 조금 느리다.
반면 포워드는 서블릿이 직접 응답하지 않고, 서버 내부에서 다른 요소에게 넘기는 방식이다. 서버 내에서의 이동이 되어서 주소는 그대로 유지되며, 데이터 또한 유지되어 속도도 상대적으로 빠르게 된다.
다만, 이 완벽해보이는 서블릿의 단점이 있으니… 바로 출력의 번거로움이다. 위 코드를 보면 알다시피 모두 out.println과 같은 형식으로 출력해야하게 된다, 이것은 작업자로 하여금 너무 큰 피로를 수반하게 된다. 이게 바로 JSP의 탄생 배경이 되었다.
8. JSP
JSP(Java Server Pages)는 "HTML 안에 자바 코드를 심을 수 있는 기술"이다. 앞서 배운 서블릿(Servlet)이 자바 코드에서 번거롭게 HTML을 넣었기 때문에, 이에 대한 보완으로 나타난 것이다. 자바 안에 HTML을 넣기 힘들다면, 반대로 HTML 속에 자바 코드를 심자는 발상 아래에서 나타난 것이다.
다만 브라우저는 사실 JSP를 직접적으로 읽지 못한다. 이 때문에 .jsp 파일은 WAS에 의해 자동으로 '서블릿(.java)' 파일로 변환되어, 컴파일 및 실행된다.
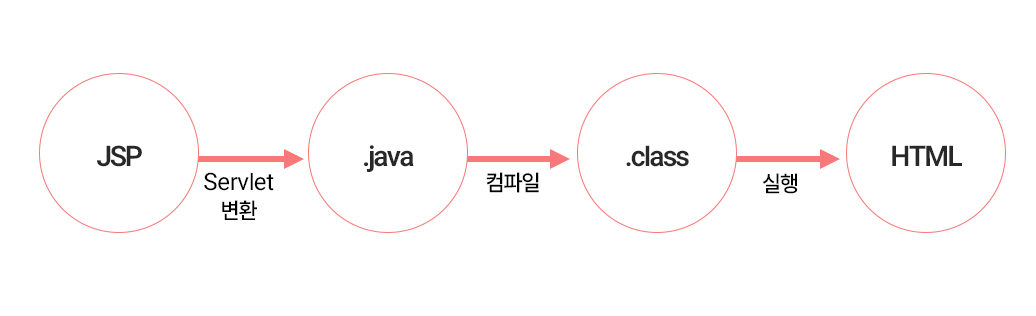
이 JSP는 결국 HTML 문서 안에 자바 코드를 끼워 넣는 기술이 필요한 것인데, 다음 네 개는 그 대표적인 기술들이다.
(1) 선언문 (Declaration)
<%! ... %>
JSP 페이지에서 사용할 변수나 메서드를 미리 정의해두는 곳이다. 여기서 선언한 변수는 페이지가 닫힐 때까지 살아있는 '멤버 변수'가 된다.
(2) 스크립트릿 (Scriptlet)
<% ... %>
가장 일반적인 자바 코드 실행 구역이다. if, for 같은 제어문을 쓰거나 계산 로직을 짤 때 사용한다. 단, 코드가 너무 많아지면 HTML 태그와 뒤섞여서 나중에 알아보기 힘들어지게 된다.
(3) 표현식 (Expression)
<%= ... %>
자바 변수에 담긴 값이나 계산 결과를 화면에 바로 출력할 때 사용한다. out.print()를 짧게 줄여 쓴 것이라 보면 된다. 다만 이 방식은 자바 코드를 직접 써야해서 생각보다 길어지게 된다.
(4) EL (Expression Language)
${Object}
위의 표현식(<%= %>)의 업그레이드 버전이다. 훨씬 짧고 간결하게 데이터를 출력한다. JS로 보면 템플릿 리터럴(Template Literals)과 같은 조금 더 업그레이드 된 방식이라고 보면 된다.
자바 코드를 직접 쓰지 않고도 내장 객체를 통해 request나 session에 담긴 값을 이름만으로 가져올 수 있다. 이 EL은 JSTL에도 사용되는데, 이는 나중에 다룰 예정이다.
9. 요청 처리의 실무 포인트
이러한 요청이 들어올 때, 그냥 온 것을 바로 받아 처리한다로만은 부족한 경우가 많다. 여기서는 실무에서 자주 언급되는 요청 처리 관점을 짧게 정리해보기로 한다.
(1) 인코딩(UTF-8)을 먼저 맞춘다
POST로 한글이 들어올 때 깨지는 경우가 있는데, 이는 한글이 멀티 바이트의 문자이기 때문이다. 이 때는 보통, 요청 본문을 읽기 전에 request.setCharacterEncoding("UTF-8") 같은 처리를 해주는 흐름이 일반적이다. GET은 환경/설정에 따라 달라질 수 있어서, "왜 글자가 깨졌는지"를 볼 때는 요청 방식(GET/POST)까지 같이 보는 편이 좋다.
(2) 클라이언트 입력은 기본적으로 믿지 않는다
폼이든 쿼리스트링이든, 사용자가 보낸 값은 검증 대상으로 보는 게 안전하다. 숫자/날짜/길이/허용 문자 같은 서버 쪽 검증을 한 번 거치는 게 기본이고, "프론트에서 한 차례 필터링했으니 괜찮겠지"는 좀 안일한 대처가 될 수 있다.
(3) 민감한 정보는 GET으로 보내지 않는다
앞에서도 말했듯 GET은 URL에 데이터가 노출되기 쉽다. 로그인, 토큰, 개인정보 성격이 강한 값은 POST(또는 적절한 방식) + HTTPS 쪽을 고려하는 게 일반적이다.
(4) redirect와 forward를 상황에 맞게 쓴다
7절에서 말했듯, redirect는 브라우저가 새 주소로 다시 요청하는 방식이고 forward는 같은 요청 안에서 서버가 다음 자원으로 넘기는 방식이다. 여기서는 실무에서 무엇을 기준으로 고르면 좋은지만 짚어본다.
URL을 바꾸고 싶을 때는 redirect가 자연스럽다. 특히 등록·수정·삭제처럼 POST로 상태를 바꾼 뒤에는, 응답 화면까지 POST 흐름으로 두면 사용자가 새로고침할 때 같은 처리가 한 번 더 실행될 수 있다. 그래서 흔히 POST로 처리 → redirect로 GET 페이지(목록/상세 등)로 보내는 PRG(Post-Redirect-Get) 패턴을 쓴다.
반대로 같은 요청 컨텍스트를 유지한 채 화면만 바꾸고 싶다면(조회 결과를 다음 JSP에 넘기는 등) forward가 더 맞는 경우가 많다. 뒤로 가기·새로고침이 어떻게 느껴질지까지 생각하면, “주소는 그대로인가 / 요청이 다시 나가야 하는가”를 기준으로 고르면 선택이 수월해진다.
(5) 에러는 사용자에게 다 보여주지 않는다
개발 중에는 스택 트레이스가 도움이 되지만, 운영에서는 내부 정보(DB 주소, 쿼리, 경로)가 노출될 수 있어서 위험하다. 사용자에게는 단순한 안내, 상세는 서버 로그로 남기는 식이 흔하다고 한다.
(6) 세션/쿠키는 편의와 보안의 균형
세션으로 로그인을 유지하는 건 편하지만, 쿠키가 자동으로 따라붙는 특성 때문에 CSRF 같은 이슈와도 연결된다. 그래서 중요한 동작에는 토큰 검증, SameSite, HTTPS 같은 방어를 같이 고민해야 한다.
(7) 로그에는 민감한 정보를 남기지 않는다
요청 파라미터를 그대로 로그에 찍는 습관은 디버깅엔 편하지만, 비밀번호·토큰·주민번호 같은 값이 섞이면 사고로 이어질 수 있다고 한다. "무엇을 찍을지"를 정해두는 게 안전하다.
이 정도만 잡혀 있어도, 이후에 JSP/Spring으로 넘어갈 때 왜 이런 설정/어노테이션/필터가 존재하는지를 연결하여 이해하기가 훨씬 수월해진다.
10. 마무리하며
이렇게 우리는 백엔드 웹 프로그래밍의 기초를 알아보았다. 많은 양이 되었지만 앞으로의 공부를 위해서 기초가 되는 내용이니 정리하고 넘어가 훨씬 좋았다. 다음 주에도 이어서 백엔드 웹 프로그래밍이다. 백엔드는 4월 중순~말까지 이어지기 때문에, 4주정도는 더 백엔드와 함께할 거 같다. 아마도 다음부터는 web.xml이나 매핑, 필터/리스너, JSTL·태그 라이브러리, MVC·프론트 컨트롤러 패턴, 배포(WAR·컨텍스트 경로)를 천천히 다룰 것 같다.
이미지 출처
※ 모든 이미지는 직접 제작하거나 저작권 문제가 없는 이미지로 제작되었습니다.
웹사이트vs웹 애플리케이션: 구글 제미나이 답변 스크린샷
'부트캠프 일지 > 멀티캠퍼스 TIL' 카테고리의 다른 글
| [Java 풀스택 개발자] 백엔드 프로그래밍 편: 스프링 편 (0) | 2026.03.30 |
|---|---|
| [Java 풀스택 개발자] 시큐어 코딩편: 개발자가 알아야 할 웹 보안 (0) | 2026.03.17 |
| [Java 풀스택 개발자] 알고리즘 편#2: 알고리즘 방법론 (0) | 2026.03.09 |
| [Java 풀스택 개발자] 알고리즘 편: 무엇이 좋은 알고리즘일까? (0) | 2026.03.03 |
| [Java 풀스택 개발자] JDBC 편 : Java와 DB의 Connection, JDBC (0) | 2026.02.24 |



