
0. 들어가기에 앞서
본 포스트는 JS의 언어체계와 관련된 보충학습이다. 강의에서는 다루지 않았던, JavaScript의 이론적인 부분을 추가적으로 다루고자 한다. 3주차는 아마 jQuery와 관련된 내용이 될 듯한데, 그 전에 JS를 완전히 정리하는 것이 낫다고 생각했다. 실제로 이 포스트는 직접 JS를 다룰 때는 크게 상관이 없는, 이론적인 이야기다. 하지만 이론은 중요하다. 이론에 대해서 익히지 않으면 AI와의 경쟁력을 가질 수 없기 때문이다.
이번에는 JS가 인터프리터 언어인가에 대해서, 그리고 JS가 얼마나 유연한가, 그리고 JS의 변수 관리 체계에 대해서 집중한다.
1. JavaScript는 인터프리터 언어다?
강사님께서 JS에 대해서 설명하시면서 말씀하신 것이 있다. JavaScript는 인터프리터 언어라는 점. 그 말을 듣고 이번 보충학습을 결정했다. JS는 정말 신기하고 이상한 언어다. HTML과 CSS와도 차이가 있을 뿐더러(애초에 JS를 다뤄야 개발자로 인정되기도 하니까) 그 유연성도 체계도 다른 언어와는 분간이 된다.
먼저 JavaScript의 언어 중 특이한 점은, 인터프리터 언어라고 적혀 있지만 사실상 컴파일도 실행한다는 것이다. 인터프리터와 컴파일러? 개념에 대해서 생소한 사람이 많을 테니 그 부분부터 짚어보자.
인터프리터 vs 컴파일러
인터프리터 언어Interpreted Language란? 소스 코드를 한 줄(문장)씩 해석하고 실행하는 프로그래밍 언어다. 따라서 해당 언어는 즉시 실행된다. 이식성이 높고, 한 줄씩 실행하므로 오류가 나는 위치 파악이 쉬워 디버깅도 용이하다. 다만, 한 줄씩 실행하므로 컴파일러 언어보다는 느릴 수 있다.
간단히 다음 코드를 확인해보자.
function add(a, b) {
return a + b;
}
let result = add(5, 3);
console.log(result);
인터프리터 방식이라면 이 코드를 다음처럼 동작한다.
소스 코드 → 한 줄씩 읽기 → 즉시 실행 → 다음 줄로 이행
예제 코드를 이미지로 표현하면 다음과 같다 할 수 있다.

반면 컴파일러 방식이라면 다음처럼 동작한다.
소스 코드 → 전체 번역 → 기계어 파일 생성 → 실행
이 또한 이미지로 표현하면 다음과 같다 할 수 있다.

온라인 게임에 비유하면, 맨 처음 데이터를 전부 받기 위해서 오래동안 기다려야하는 게임이 있고, 중간중간에 통신을 하면서 다운로드를 받기 때문에 중간에 로딩이 걸리는 게임이 있다. 전자가 컴파일러고 후자가 인터프리터다. 대표적인 인터프리터 언어로는 Python, JavaScript, Ruby, PHP가 있고, 컴파일러 언어로는 C, C++, Java, C#, Swift, Go가 있다.
인터프리터 언어와 컴파일러 언어의 비교는 다음과 같다.
| 항목 | 인터프리터 언어 | 컴파일러 언어 |
| 실행 방식 | 한 줄씩 해석 후 즉시 실행 | 전체 코드를 기계어로 변환 후 실행 |
| 실행 속도 | 느림 (매번 해석 필요) | 빠름 (이미 기계어로 변환됨) |
| 시작 시간 | 빠름 (바로 실행) | 느림 (컴파일 시간 필요) |
| 이식성 | 높음 (인터프리터만 있으면 됨) | 낮음 (플랫폼별 컴파일 필요) |
| 디버깅 | 쉬움 (오류 위치 즉시 파악) | 어려움 (컴파일 후 실행) |
| 메모리 사용 | 많음 (인터프리터 상주) | 적음 (실행 파일만) |
| 배포 | 소스 코드 그대로 배포 | 실행 파일(.exe 등) 배포 |
| 코드 보안 | 낮음 (소스 코드 노출) | 높음 (기계어로 변환) |
| 수정 용이성 | 높음 (즉시 반영) | 낮음 (재컴파일 필요) |
Google V8 엔진의 개발
이 때문에 전통적으로는 JavaScript는 컴파일러가 아닌 인터프리터언어라고 할 수는 있다. 그러나 2008년 9월 2일에 구글이 V8을 발표하면서 이야기는 좀 달라졌다. V8은 오픈소스인 JavaScript 및 WebAssembly 엔진으로, 현재까지도 깃헙 레퍼지토리에 공유되고 있다. C++로 작성되어 ECMAScript를 지원한다. 현재 Google Chrome과 Node.js에서 사용되고 있다.
구글이 V8을 발표한 시기는 Google Chrome이라는 웹 브라우저를 발표한 시기와 동일한데, Google Chrome을 위해서 V8을 개발했다고 볼 수 있다. 따라서 Internet Explore보다 구글 크롬이 빨랐던 이유는, V8이 기여한 바가 크다. 물론 그 외에도 Chrome이 IE보다 빠른 이유는 여러 가지 더 있겠으나 그 중 하나가 V8 엔진의 개발 및 사용이다.

V8은 JIT 컴파일을 통하여 JavaScript를 컴파일하여 사용한다. 여기서 JIT는 Just-In-Time의 준말로, 동적 번역이라고도 한다. 프로그램을 실제 실행하는 시점에 기계어로 번역하는 컴파일 기법이다. 정적 번역의 경우 실행 전 무조건 컴파일을 해야하기에 다양한 플랫폼에 맞게 컴파일을 하려면 시간이 오래 걸린다. 이를 보완하기 위한 부분이 동적 번역- JIT 컴파일인 것이다.
그렇다면 V8은 어떻게 컴파일을 하는 것일까? 전통적인 방법과 같이 비교를 해보자.
기존 JS의 인터프린팅 과정 대 V8의 컴파일링 과정
대표적인 바닐라 인터프리팅 JS 엔진은 SpiderMonkey라고 할 수 있다. SpiderMonkey는 Mozilla에서 사용하고 있는데, Mozilla의 대표 브라우저는 바로 파이어폭스다. 1996년 3월에 발표된 SpiderMonkey는 V8이 개발되기 전부터 존재했다고 할 수 있다. 그렇다면 간단히 SpiderMonkey와 V8의 비교를 통해서 과정의 비교를 해보고자 한다.
코드 실행의 기본 원리
소위 말하는 고급언어/프로그래밍 언어로 우리가 코드를 작성하면, 이 코드는 인터프리팅이나 컴파일 등의 과정을 통해 기계어로 변환된다. 기계어는 0과 1로 이루어진 이진법의 언어이다. 이것을 컴퓨터가 이해하고, 메모리에 할당하여 코드를 읽고 실행한다. 즉 다음과 같은 과정을 거친다고 할 수 있다.

그러나 인터프리터는 여기에 한 가지가 더 추가된다. 그것이 바로 바이트코드Bytecode이다. 바이트코드는 사람이 작성한 고급언어/프로그래밍 언어를 기계어로 번역하기 위해서 한 차례 거치는 '중간 단계'라고 할 수 있다. 이 바이트코드가 어째서 인터프리팅에 필요하냐면, 바로 그 특이성 때문이다. 한 줄마다 분석하여 실행하기 때문에, 바이트코드를 거쳐 기계어로 번역을 한 차례 거칠 수밖에 없다. 혼자서 외국어 공부를 할 때는 외국인의 말을 전체 통역해도 괜찮겠지만, 외국인과 대화할 때는 하나하나 통역을 할 수밖에 없다. 그리고 이 통역을 담당하는 것이 통역사이듯, 바이트코드 또한 중간단계라고 할 수 있다.
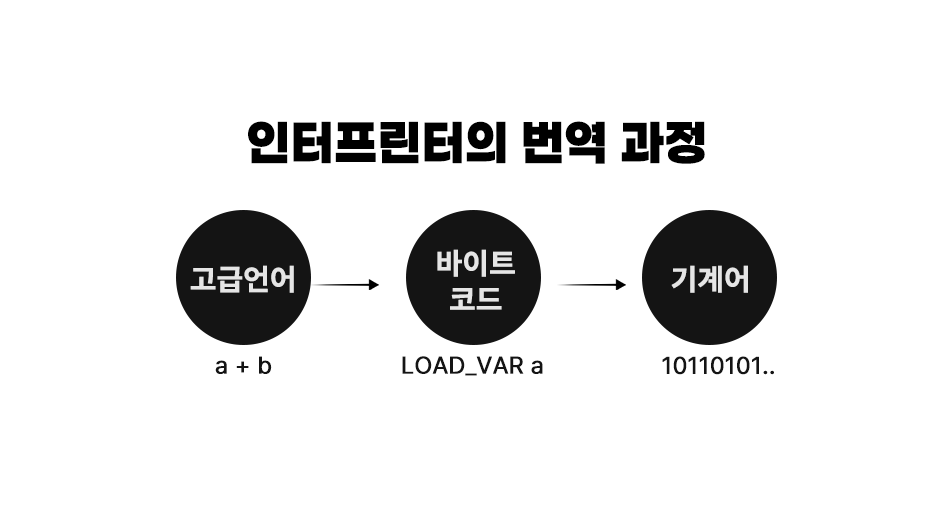
JS의 기본 엔진 구조
SpiderMonkey를 포함하여 전통적인 JS의 기본 엔진 구조에서는 이 바이트코드로 변환하는 과정이 있다. 단순히 고급언어가 바이트코드가 바로 변환되는 것이 아니기 때문에, 몇 가지의 과정을 거치게 된다. 이는 다음과 같은 그림으로 나타낼 수 있다.

각 과정에 대해서 추가 설명을 붙인다.
1) 토크나이저Tokenizer
JS 코드를 어휘 분석Lexical Analysis하여 토큰으로 만드는 것을 바로 토큰화라고 할 수 있다. 위 a+b의 경우 다음과 같은 코드가 된다.
[
{
"type": "Keyword",
"value": "function"
},
{
"type": "Identifier",
"value": "add"
},
{
"type": "Punctuator",
"value": "("
},
{
"type": "Identifier",
"value": "a"
},
{
"type": "Punctuator",
"value": ","
},
{
"type": "Identifier",
"value": "b"
},
{
"type": "Punctuator",
"value": ")"
},
{
"type": "Punctuator",
"value": "{"
},
{
"type": "Keyword",
"value": "return"
},
{
"type": "Identifier",
"value": "a"
},
{
"type": "Punctuator",
"value": "+"
},
{
"type": "Identifier",
"value": "b"
},
{
"type": "Punctuator",
"value": ";"
},
{
"type": "Punctuator",
"value": "}"
},
…(생략)
]
고작 function add(a, b) { return a + b; }의 간단한 코드지만 이렇게 세분화해서 토큰으로 만든다. 타입을 각자 나눠서 어떠한 역할을 하고 있는지 확인한다.
2) 파서Parser
파서는 이 토큰들을 받아 분석하여 AST(Abstract Syntax Tree)를 만든다. 추상 구문 트리라고 하는데, 예전에 다뤘던 DOM처럼 각 코드의 구조를 트리 형태로 표현하는 것이다.

토큰화는 파싱의 첫 단계이기 때문에, 파서(Parser)에 포함되어 설명된다. 이 파서 전체 과정에 대해서 간단히 말하면 번역기가 돌아가는 것과 비슷하다. 남자가 걷는다를, A man is walking으로 번역하기 위해서는, 남자/가/걷는다로 분할해야 한다. 그리고 남자는 명사, 가는 조사, 걷는다는 동사로 구조를 분석하여, 각각의 단어를 영어로 바꾸는 것이다. 이에 대해서는 아래 이미지와 같이 이해할 수 있다.
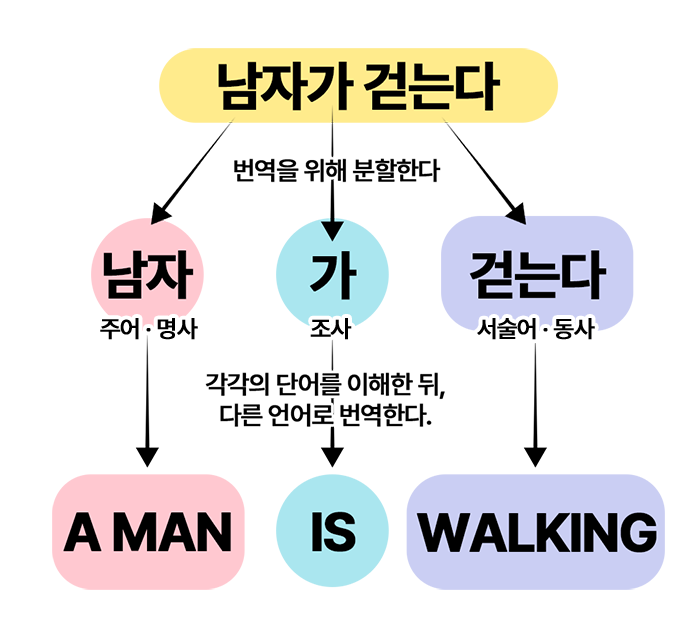
토큰과 AST에 대해서는 다음 링크에서 확인할 수 있다(링크).
3) 인터프리터Interpreter
AST를 바이트코드로 변환한다. 그러면 가상머신에서 이 바이트코드를 받아 기계어로 번역한다.
V8의 엔진 구조
그리고 V8은 여기에서 컴파일을 추가한다. AST가 만들어진 후, Ignition에 의해 인터프리팅이 된다. 그리고 이 ignition은 코드를 실행하며 프로파일, 그리고 피드백 데이터를 수집한다. 이를 통해 반복 사용 여부나 코드의 양 등을 판단하여 TurboFan을 보내고, TurboFan이 최적화 과정을 거친다. 여기서 이 TurboFan에 의한 최적화가 바로 컴파일이라고 할 수 있다. 이 과정은 위에서 설명했듯 JIT 컴파일 방식이다.
본래는 Full-Codegen이라고 하는 JIT 컴파일러를 사용했는데, Full-Codegen은 전체 파일을 한 차례 컴파일하는데, 이것이 메모리 점유를 많이 하기 때문에 Ignition과 TurboFan에 의해서 인터프리팅과 최적화 컴파일링으로 메모리 점유를 낮추고, 기존 전통적인 방식보다 더 빠르게 구동할 수 있도록 실행할 수 있게 만든 것이다. 이에 따른 과정은 다음처럼 거친다고 할 수 있다.
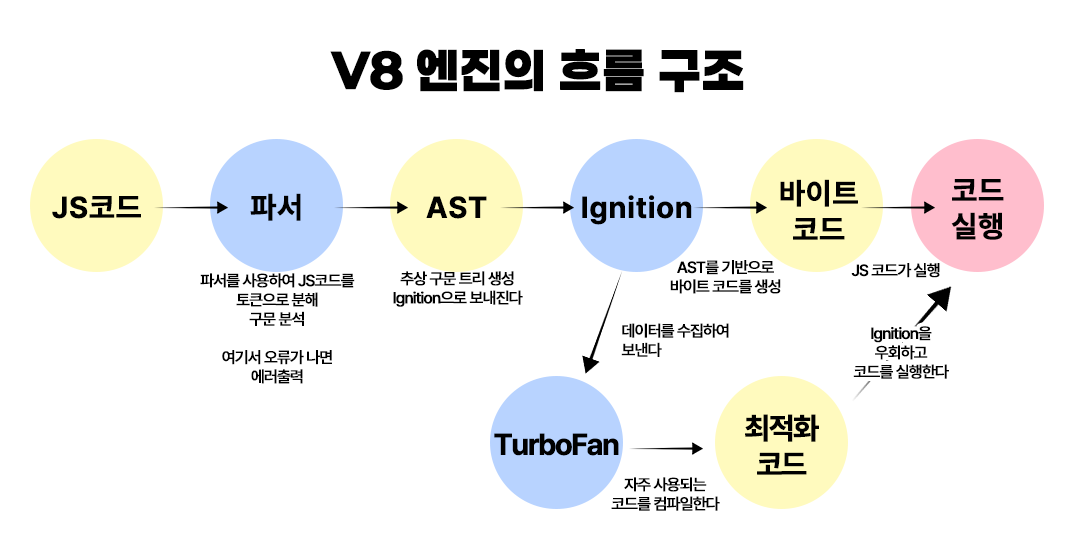
구글 크롬 그리고 크로미움Chromium이 등장한 이후 웹 브라우저에 다양한 크로미움 기반 브라우저들이 출시됨에 따라서 V8은 현재 JS의 대표 엔진 중 하나라고 보아도 좋다. 그러므로 현재의 JS는 컴파일러를 사용하는 인터프리터 언어라고 할 수 있다.
2. JS의 유연성
다음으로는 JavaScript가 얼마나 이상한(?) 언어인가를 정리해보고자 한다. 그 특징 중 하나는 바로 엄격하지 않다는 점이다. 다른 프로그래밍 언어의 경우, 규칙에 엄격한 경우도 많기 때문에(당장 Java만해도 그러하다), JS를 사용하는 감각으로 다른 언어를 사용하면 오류가 날 수 있다. 그러면 JS의 유연성을 구성하는 것들은 무엇이 있을까?
동적 타이핑Dynamic typing
동적 타이핑이란 데이터 타입을 직접 선언하지 않아도 엔진에서 알아서 값을 바탕으로 타입을 지정해주는 것을 의미한다. 미리 각 변수의 데이터 타입을 선언해야하는 정적 타이핑Static typing과는 다르다. 여기서 타이핑typing이란, 변수의 데이터 타입을 정해주는 걸 의미하는데, 문자열(String)이냐 정수(Int) 혹은 실수(Float)이냐를 먼저 정하는 것이다.
정적의 경우, 타입을 한 차례 정하고 나면 형변환하지 않을 경우 다른 타입 값을 넣을 수(재할당 할 수) 없다. 반면 동적은 타입을 정했다고 하여도 다른 타입의 값을 재할당할 수가 있다. 그러면 이렇게 생각할지도 모른다.
그러면 동적이 무조건 좋은 게 아닐까?
이런 동적 타이핑 방식이 JS의 유연함에 도움이 되는 것은 맞다. 그러나 예전 변수의 키워드를 정리할 때 우리가 변수 오염의 위험이 있다고 지적한 것처럼, 너무 많은 자유는 오히려 해가 될 수 있다. 자유가 많으면 프로그래머가 인지할 수 있는 장소가 아닌 곳에서 코드가 일어날 수 있다. 이에 따라 동적 타이핑 언어는 의도치 않은 타입 변환으로 프로그래머가 의도한 것과 다른 결과를 불러일으킬 수 있다.
그러하여 JS 사용하는 사람들 중 변수의 타입을 엄격하게 지정하는 사람도 많다. a는 실수, b는 문자열처럼.
자동 형변환
JS의 유연성 중 하나는 자동 형변환이 자유롭다는 것이다. 여기서 형변환이라는 것은 Type Coercion이라고 하는데, 즉 위에 있는 타이핑과도 관련이 있다. 자동 형변환을 풀어 쓰면 변수의 타입을 자동으로 변환해준다라고 할 수 있는데, 말 그대로 문자열에서 숫자로, 숫자에서 문자열로 JS 엔진에서 임의로 해석하여 변환시켜준다는 것이다.
다음과 같은 코드를 보자.
var a = '3';
if(a == 3) { console.log('정답입니다!'); }
여기서 3 앞 뒤에 따옴표가 있기 때문에 3은 문자열이어야 한다. 타입이 문자열인 a와, 타입이 숫자인 3은 같을 수가 없다. 그러나 직접 실행해보면 콘솔에서 정답입니다! 메시지가 나타날 것이다. JS가 아! a는 숫자구나! 하고 비교문에서 임시적으로 형변환한 것이다. 그렇기 때문에 명시적으로 형변환을 하여(강제 형변환) a를 굳이 숫자로 바꿀 필요는 없다.
그러나 빛이 있으면 어둠도 있는 법, 위에서 동적 타이핑에 대한 단점을 지적한 것과 마찬가지로, 이 자동 형변환은 예상치 못한 버그들이 생기기 쉽다. JS에서 비교문을 할 때 엄격한 규칙('===')으로 비교를 하라는 말이 있었을 텐데, 그게 바로 이 자동 형변환 때문이다.

프로토타입 기반 상속
프로토타입 상속prototypal inheritance은 JS의 고유 기능이다. 이 프로토타입 상속은 만화 〈나루토〉에서 나루토가 보이는 다중 그림자 분신술로 간단히 비유할 수 있다. 각각 다르게 움직일 수 있지만, 자신이 쓸 수 있는 기술(인술)은 본체인 나루토의 것을 사용하게 된다.

반면 나루토가 익히지 않은 기술이라면 분신들도 쓸 수 없다. 분신은 기술을 쓸 때마다 본체를 참조하여 그 기술을 배웠는지 확인한다. 이게 바로 프로토타입 상속이다. 즉, 여기서 프로토타입은 나루토 본체를 의미한다.
JS에서 객체Object는 명세서에 명명한 [[프로토타입Prototype]]이라는 숨김 속성Property을 가지게 된다. 보통 이 숨김 속성은 null이거나 다른 객체에 대한 참조를 하게 된다. 그 참조 대상은 프로토타입이라고 부른다. 만약 객체에서 속성을 찾으려 하는데 해당 속성이 없다면, JS는 바로 이 프로토타입에서 참조를 한다. 만약에 프로토타입에도 속성이 없다면, 그 프로토타입의 프로토타입에게서도 속성을 찾으려고 한다.이렇게 계속 올라가는 것을 프로토타입 체인Prototype Chain이라고 한다.
기왕 나루토 이야기가 나온 김에 코드도 그렇게 보도록 하자.
class 닌자 {
constructor(name) {
this.name = name;
}
인사() {
return `내 이름은 ${this.name}라고!`;
}
}
const 나루토 = new 닌자('나루토');
console.log(나루토.인사()); // '내 이름은 나루토라고!'
console.log(나루토.__proto__ === 닌자.prototype); // true
여기서 닌자라는 클래스가 프로토타입이 된다. constructor는 닌자를 만들 때 그 이름을 받는다. 인사() 메서드는 모든 닌자가 공유하는 기술(인술)이 된다. const 나루토를 통해 새로운 닌자 나루토가 만들어졌다(객체 생성). 나루토는 닌자이므로, 닌자로부터 상속을 받는다. 나루토에게 인사() 메서드를 시킨다. 나루토에게는 인사()는 없다. 그러나 나루토는 닌자이고, 닌자는 인사() 메서드를 가진다. 이렇게 나루토는 인사() 메서드를 실행할 수 있게 된다.
다만 이런 프로토타입 상속에서의 상속 속성Property은 대부분의 객체 순회 메서드에서는 나타나지 않는다. Object.keys(), Object.values() 같은 메서드들은 객체 자신의 속성만 반환하기 때문이다. 예외적으로 for...in 루프는 프로토타입 체인까지 순회한다.
이러한 프로토타입 상속이 있기 때문에 JS의 유연성이 조금 더 보탬이 되지만 … 문제는 어렵다는 점. 클래스 기반 언어의 개발자들에게 JS는 어렵다고 하는 대표적인 이유 중 하나이다. 그리고 프로토타입을 건드리면 그 상속을 받는 객체들도 영향을 받는다. 이 부분도 의도치 않은 오류가 일어날 수 있다.
그리고 private의 구현에 문제가 있다. private는 비공개 속성private attribute의 준말인데, 클래스 바깥에서는 접근할 수 없고 클래스 안에서만 사용할 수 있다. private가 중요한 이유는 캡슐화Encapsulation 때문이다. 그 말 그대로 단단한 껍질이 외부에서의 공격을 막아주기 때문에(외부의 선언 등에 영향을 받지 않으므로), 데이터를 보호할 수 있었다. 그러나 private가 없으면 이것이 불가능하다.
그러하여 ES2015부터 class 문법이 추가되어 클래스 기반 언어의 개발자들이 이해하기 쉽게 되었고, ES2022부터는 # 문법으로 진짜 private 속성도 구현할 수 있게 되었다.
일급 함수
MDN의 정의에 의하면, 프로그래밍 언어는 해당 언어의 함수들이 다른 변수처럼 다루어질 때 일급함수를 가진다고 한다. 잠깐, 이 이야기 어디에서 많이 봤는데? 바로 콜백함수에 대한 포스팅을 했을 때다.
[Java 풀스택 개발자] #특별편(보충학습) - 콜백 함수에 대해
0. 들어가기에 앞서본 포스트는 javascript 내의 함수 중에 콜백함수(callback function)에 대한 보충학습이다. 콜백함수에 대한 이론과 함께 콜백함수의 종류가 무엇인지에 대해서 다루고자 한다. 기본
bbbbabbbababababa.tistory.com
JavaScript에서는 함수를 인자로서 사용할 수 있다. 따라서 콜백 메서드가 다른 경우보다 간단하게 성립이 되는 경우가 많다. 이 일급 함수가 지원되지 않는 언어에서는 콜백을 사용할 때는, 함수를 객체로 정의한 후에야 쓸 수 있다. 그리고 이러하기 때문에 코드의 재사용이 어렵고, 코드가 장황해지는 단점이 있다. 콜백 메서드의 이점에 대해서는 위 포스팅에서 그대로 적어두었으니 참고하면 좋다.
3. JS의 변수 관리 체계
그렇다면 마지막으로 JavaScript의 변수 관리 체계에 대해서 알아보고자 한다. 변수에 대한 정의는 이미 몇 번 복습하였으니, JS의 변수 관리 체계의 특이성에 주목해보겠다. 여기서는 스코프Scope와 클로저Closure라는 개념이 등장한다. 스코프는 이미 과거 포스팅에 적었으나, 다시 한번 이렇게 정의하겠다.
스코프란?
변수를 사용할 수 있는 범위를 의미한다.
JavaScript의 스코프 타입은 바로 렉시컬 스코프이다.
렉시컬 스코프Lexical Scope
다른 말로는 정적 스코프Static Scope라고도 한다. 함수가 호출 위치가 아니라 선언 위치에 따라 결정되는 것을 의미한다. 다음 두 코드를 확인해보자.
const x = 1;
function outer() {
const x = 10;
function inner() {
console.log(x);
}
inner();
}
outer(); // 10
function outer() 내에 function inner()가 존재한다. 그리고 outer를 호출할 때, inner를 선언한 뒤 inner를 호출한다. 이에 따라 콘솔에는 x의 값인 10이 찍힌다.
const x = 1;
function outer() {
const x = 10;
inner();
}
function inner() {
console.log(x);
}
outer(); // 1
반면 이 경우의 경우 둘은 독립적으로 선언되어 있다. outer 내에 inner를 호출했다. 하지만 콘솔에 찍힌 x의 값은 1이 찍힌다. 이것이 바로 렉시컬 스코프의 특징이다. 선언의 위치가 어떻게 되느냐에 따라서 변수의 영향을 받기도, 받지 않기도 한다. 즉 호출의 위치는 관련이 없고, 선언의 위치에 따라 상위 스코프를 결정한다는 의미이다.
반면 동적 스코프Dynamic scope는 호출에 따라서 상위 스코프가 결정된다. 만약 JS가 동적이었다면, 아래의 코드 또한 콘솔에 10이 찍혔을 것이다.
그런데 여기에서, 전역 변수Global Variable은 어떻게 인식되는 걸까? 이를 알려면 스코프 체인에 대해서 알아야 한다.
스코프 체인Scope Chain
스코프 체인의 선행 개념으로서 먼저 이야기할 것은 실행 컨텍스트Execution context이다. 실행 컨텍스트는 JavaScript의 코드가 실행될 때 만들어지는 환경을 의미한다. 코드를 실행하기 위해서는 각각 변수, 함수, 외부 환경 등에 대한 정보를 담아둘 곳이 필요한데, 이게 바로 실행 컨텍스트이다. 이렇게 정의하면 잘 와닿지 않는데, 사무실 컴퓨터의 비밀번호를 적어두는 포스트잇 같다. 우리는 컴퓨터를 로그인 할 때마다(함수를 실행할 때마다) 모니터에 붙어있는 포스트잇(실행 컨텍스트)의 비밀번호(변수 혹은 함수)를 확인하고 로그인한다.

실행 컨텍스트에는 두 가지 종류가 있다. 전역 실행 컨텍스트(Global Execution Context)와 함수 실행 컨텍스트(Function Execution Context)이다. 전역 실행 컨텍스트는 코드가 처음 실행될 때 만들어지며, 단 하나만이 존재한다. 전역 변수들이 여기에 저장된다. 함수 실행 컨텍스트는 함수가 호출될 때마다 생성된다. 여러 개가 동시에 존재할 수 있으며, 각 함수의 지역 변수들이 여기에 저장된다.
여기까지 이해가 되었다면 스코프 체인에 대해서 이야기할 차례이다.
스코프 체인은 그야말로 각 스코프가 어떻게 연결되어 있는가를 나타내는, 일종의 리스트다. 실행 컨텍스트는 LIFO(Last in, First out) 구조를 가진 스택으로 관리된다. 코드가 실행되는 동안 생성된 모든 실행 컨텍스트가 이 스택에 쌓이고, 가장 나중에 들어간 것이 가장 먼저 나온다. 다음 코드를 보자.
var x = 'global';
function outer() {
var x = 'local';
function inner() {
console.log(x);
}
inner();
}
outer();
코드가 실행되면 가장 먼저 전역 실행 컨텍스트가 스택에 쌓인다. 이후 outer() 함수가 호출되면서 outer 실행 컨텍스트가 그 위에 쌓이고, inner() 함수가 호출되면서 inner 실행 컨텍스트가 최상단에 쌓인다.
변수를 찾을 때는 스택의 최상단 즉, 가장 마지막에 호출된 inner의 실행 컨텍스트부터 탐색을 시작한다. inner에서 x를 찾지 못하면 한 단계 아래인 outer로 내려가고, 거기서도 없으면 전역까지 내려간다.

이것이 스코프 체인을 통해 변수를 찾는 과정이다. 만약 전역까지 내려갔는데도 변수를 찾지 못하면 오류가 발생한다. JavaScript에서는 스코프 체인 덕분에 상위 스코프의 변수를 자유롭게 참조할 수 있어, 매번 변수를 선언할 필요가 없다.
클로저Clousre
MDN의 정의에 의하면 클로저는 주변 상태(어휘적 환경)에 대한 참조와 함께 묶인(포함된) 함수의 조합이라고 적혀있다. 간단히 말하면, 함수가 자신이 정의된 위치의 변수를 기억하고, 그 함수가 외부에서 실행되어도 그 변수에 접근할 수 있는 것을 의미한다. 잘 모르겠다면 다음 코드를 확인해보자.
function outer() {
const message = 'hello'; // outer의 변수
function inner() {
console.log(message); // outer의 message 사용
}
return inner;
}
const func = outer(); // outer 종료
func(); // 'hello' 출력
inner는 자신의 밖에 있는 변수인 message의 값을 '기억'하고 있다. 그리고 outer를 호출한 결과(inner 함수)가 func에 저장되는데, 이 상태에서 outer는 종료된다. 그러나 그럼에도 func를 호출하면 그대로 inner는 자신이 기억하고 있는 message의 값을 포함하여 콘솔로 로그를 보낸다. 이것이 바로 클로저다.
클로저의 조건
다만, 이 클로저가 되기 위해서는 3가지의 조건이 필요하다.
1) 함수 안에 함수인 중첩 함수 구조일 것.
2) 내부 함수가 외부 함수의 변수를 참조할 것.
3) 내부 함수가 외부로 반환되거나 외부에서 실행 가능해야할 것.
이 세 가지의 조건을 만족하지 못하면 클로저라고 할 수 없다.
클로저의 용도와 작동 원리
이러한 클로저의 용도는 데이터 은닉, 상태 유지, 콜백/이벤트 핸들러로서의 사용 등등이 있다. 이것이 JS의 단점을 보완해준다. 위 프로토타입 상속에서 private의 사용이 어렵다는 이야기를 했었는데, 그 private를 클로저가 대신하기도 했다. 즉, 캡슐화의 이점이 있다. 그러나 단순히 저것만 봐서는 클로저가 어떻게 데이터를 은닉하는가, 캡슐화하는가에 대해 의아하므로 조금 더 살펴보기로 한다.
위에서 MDN의 정의에 의하면 클로저는 주변 상태(어휘적 환경)에 대한 참조와 함께 묶인(포함된) 함수의 조합이라고 적혀 있다. 여기서 어휘적 환경Lexical Environment이 중요한데, 함수는 생성될 당시 자신이 선언된 어휘적 환경을 내부에 저장한다. 프로토타입이 [[Prototype]]에 저장되듯이, 어휘적 환경도 [[Environment]]에 저장되는 것이다. 프로토타입과 마찬가지로 이 또한 숨은 속성Property이다.
그리고 내부 함수는 외부 함수의 어휘적 환경을 참조한다. 여기서 연결이 되는데, inner 함수를 반환하면, 외부 함수가 종료된다고 해도 이 참조는 유지된다. 보통의 경우는 함수가 끝나거나 할 경우, 가비지 컬렉터Garbage Collector가 제거하고는 한다. 여기서 가비지 컬렉터는 JS 엔진 내에 내장된, 메모리 자동 관리 시스템이다. 사용하지 않는 메모리(변수나 함수가 저장되어 있는 곳들)을 청소하고는 한다. 그러나 이 경우는 다르다. inner 함수는 지금 outer의 어휘적 환경을 참조하고 있다. 그러므로 가비지 컬렉터는 제거하지 않는다. 그러므로 이 참조는 남은 상태로, 저장된 참조를 따라가 외부 함수의 변수에 접근할 수 있게 된다.

그러므로 내부 함수는 외부 함수의 변수에는 여전히 접근이 가능하므로 작동이 가능하다. 그러나 어휘적 환경에 접근할 수 있는 건 오로지 내부 함수 뿐이다. 외부에서는 다른 함수의 어휘적 환경을 참조할 수가 없다. 이로서 내부에서는 조작이 가능하되, 외부에서는 그 내용을 알 수 없게 되는 완전한 밀실이 완성 되었다. 이렇게 클로저는 데이터를 은닉하게 된다.

4. 마무리하며
이로서 JS의 언어 체계에 대한 이론적인 내용을 정리할 수 있게 되었다. 다른 언어와 다른 JS만의 특징은 분명히 장점도 있고 단점도 있다. 이렇기 때문에 다른 언어를 배운 사람들은 막상 JS를 마주하면 어렵다고 이야기한다고 한다. 그러므로 확실히 JS만의 개성을 확인해야만 한다. 코드와 문법을 외우는 것은 분명히 중요하지만, 암기만으로는 JS를 정복할 수 없다. 다음 편은 jQuery에 대한 정리를 쓸 예정인데, 아마 여태까지 했던 이론보다는 좀 더 실습과 코드 리뷰를 다루게 될 예정이다.
'부트캠프 일지 > 멀티캠퍼스 TIL' 카테고리의 다른 글
| [Java 풀스택 개발자] React의 언어체계 (0) | 2026.01.26 |
|---|---|
| [Java 풀스택 개발자] jQuery 실전- localStorage 활용 Todo List (0) | 2026.01.19 |
| [Java 풀스택 개발자] JavaScript 완전 정복! (0) | 2026.01.13 |
| [Java 풀스택 개발자] #특별편(보충학습) - 콜백 함수에 대해 (0) | 2026.01.12 |
| [Java 풀스택 개발자] HTML과 CSS의 구성에 대해 (0) | 2026.01.06 |



